
%20--%3e%3cpath%20d='M44.0926,29.656v-11.488h2.048v9.696h5.408v1.792h-7.456ZM52.7619,20.136v-1.968h1.984v1.968h-1.984ZM54.7138,21.256v8.4h-1.92v-8.4h1.92ZM60.2834,29.832c-2.4,0-4.08-1.776-4.08-4.368,0-2.464,1.664-4.368,4-4.368,2.432,0,3.728,1.84,3.728,4.144v.64h-5.888c.144,1.44,1.008,2.32,2.24,2.32.944,0,1.696-.48,1.952-1.344l1.648.624c-.592,1.472-1.92,2.352-3.6,2.352ZM60.1873,22.712c-.992,0-1.76.592-2.048,1.728h3.856c-.016-.928-.592-1.728-1.808-1.728ZM66.764,25.464c0,1.712.896,2.704,2.208,2.704,1.024,0,1.648-.672,1.888-1.6l1.648.832c-.432,1.36-1.712,2.432-3.536,2.432-2.4,0-4.128-1.776-4.128-4.368s1.728-4.368,4.128-4.368c1.808,0,3.056,1.024,3.504,2.368l-1.616.88c-.24-.912-.864-1.6-1.888-1.6-1.312,0-2.208,1.008-2.208,2.72ZM73.6689,29.656v-11.488h1.92v3.984c.48-.56,1.232-1.056,2.32-1.056,1.76,0,2.816,1.216,2.816,3.024v5.536h-1.92v-4.976c0-1.04-.416-1.792-1.472-1.792-.864,0-1.744.64-1.744,1.84v4.928h-1.92ZM82.8605,27.544v-4.656h-1.168v-1.632h1.168v-2.464h1.888v2.464h1.76v1.632h-1.76v4.352c0,.752.432.832,1.12.832.32,0,.496-.016.784-.048v1.616c-.352.064-.832.112-1.328.112-1.6,0-2.464-.496-2.464-2.208ZM91.5646,29.832c-2.4,0-4.08-1.776-4.08-4.368,0-2.464,1.664-4.368,4-4.368,2.432,0,3.728,1.84,3.728,4.144v.64h-5.888c.144,1.44,1.008,2.32,2.24,2.32.944,0,1.696-.48,1.952-1.344l1.648.624c-.592,1.472-1.92,2.352-3.6,2.352ZM91.4687,22.712c-.992,0-1.76.592-2.048,1.728h3.856c-.016-.928-.592-1.728-1.808-1.728ZM96.6532,29.656v-8.4h1.92v.896c.48-.56,1.232-1.056,2.32-1.056,1.76,0,2.816,1.216,2.816,3.024v5.536h-1.92v-4.976c0-1.04-.416-1.792-1.472-1.792-.864,0-1.744.64-1.744,1.84v4.928h-1.92ZM109.2209,29.832c-2.4,0-4.08-1.776-4.08-4.368,0-2.464,1.664-4.368,4-4.368,2.432,0,3.728,1.84,3.728,4.144v.64h-5.888c.144,1.44,1.008,2.32,2.24,2.32.944,0,1.696-.48,1.952-1.344l1.648.624c-.592,1.472-1.92,2.352-3.6,2.352ZM109.1249,22.712c-.992,0-1.76.592-2.048,1.728h3.856c-.016-.928-.592-1.728-1.808-1.728ZM115.7015,25.464c0,1.712.896,2.704,2.208,2.704,1.024,0,1.648-.672,1.888-1.6l1.648.832c-.432,1.36-1.712,2.432-3.536,2.432-2.4,0-4.128-1.776-4.128-4.368s1.728-4.368,4.128-4.368c1.808,0,3.056,1.024,3.504,2.368l-1.616.88c-.24-.912-.864-1.6-1.888-1.6-1.312,0-2.208,1.008-2.208,2.72ZM124.5263,18.168v6.624l3.232-3.536h2.352l-3.168,3.264,3.424,5.136h-2.224l-2.512-3.792-1.104,1.12v2.672h-1.92v-11.488h1.92ZM134.4864,29.832c-2.4,0-4.08-1.776-4.08-4.368,0-2.464,1.664-4.368,4-4.368,2.432,0,3.728,1.84,3.728,4.144v.64h-5.888c.144,1.44,1.008,2.32,2.24,2.32.944,0,1.696-.48,1.952-1.344l1.648.624c-.592,1.472-1.92,2.352-3.6,2.352ZM134.3904,22.712c-.992,0-1.76.592-2.048,1.728h3.856c-.016-.928-.592-1.728-1.808-1.728ZM144.3435,21.24v1.92c-.24-.032-.4324-.048-.7044-.048-1.216,0-2.144.784-2.144,2.128v4.416h-1.92v-8.4h1.92v1.248c.368-.784,1.232-1.296,2.304-1.296.224,0,.4004.016.5444.032Z'%20fill='%23fff'/%3e%3cg%3e%3ccircle%20cx='20.8287'%20cy='24'%20r='15.1723'%20fill='%2346c0ec'/%3e%3crect%20x='17.1753'%20y='15.5994'%20width='3.4906'%20height='3.3509'%20fill='%23032b3a'/%3e%3cpolygon%20points='20.6658%2027.1881%2020.6658%2020.3466%2017.1753%2020.3466%2017.1753%2030.3994%2020.6078%2030.3994%2026.53%2030.3994%2026.53%2027.1881%2020.6658%2027.1881'%20fill='%23fff'/%3e%3c/g%3e%3c/svg%3e)
Hinter den Kulissen von Clarity: Wie wir unseren KI-gestützten Website-Analyser gebaut haben

Websites haben heute mehrere Rollen: sie sind Vertriebsplattform, Content-Hub und Markenbotschafterin zugleich.
Genau deshalb ist die Frage „Wie gut funktioniert diese Website eigentlich?“ so unangenehm schwer zu beantworten. SEO, Messaging, Conversion, Accessibility und technische Performance bringen jeweils eigene Tools, eigene Reports und ihre eigene Sprache mit.
Irgendwann haben wir uns gefragt, ob das nicht einfacher geht. Ein einziger Analyse-Lauf, der alles abdeckt - ohne Checkliste und auch ohne manuelles Nachfassen dafür mit aktueller KI, die Inhalte tatsächlich versteht.
Das Ergebnis ist Clarity, unsere B2B-Plattform für Website-Analysen. Mehr über die Entstehung von Clarity könnt ihr hier nachlesen.
In diesem Beitrag zeigen wir, wie Clarity technisch funktioniert und welche Überlegungen hinter der Architektur stecken.
Was Clarity macht
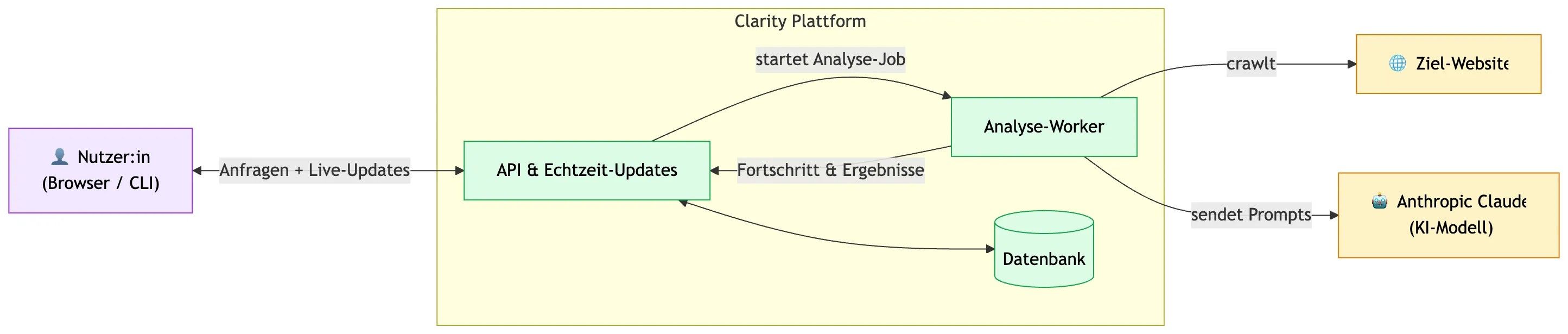
Clarity analysiert Websites so, wie es erfahrene Berater:innen tun würden: Die Plattform crawlt Seiten, identifiziert relevante URLs, führt mehrere KI-gestützte Analysen parallel aus und verdichtet die Ergebnisse zu einem klaren, handlungsorientierten Report.
Marketing-Teams nutzen Clarity für Website-Audits. Agenturen setzen es in der Angebotsphase ein. Sales-Teams gehen damit vorbereitet in Pitch-Gespräche.
Das eigentlich Spannende ist aber nicht der Output, sondern der Motor darunter. Denn jede Architekturentscheidung wurde von einer konkreten Frage getrieben:
Wie bleibt das System schnell, kosteneffizient und flexibel genug für das, was nächste Woche kommt?
Die Grundidee: Plugins statt Monolith
Viele Analyse-Tools verdrahten ihre Prüfungen fest ins Produkt ein. Neue Funktion nötig? Ticket schreiben, Priorisierung abwarten, drei Sprints später hoffen, dass sie live geht.
Clarity ist anders aufgebaut.
Im Kern steht ein Plugin-System. Jede einzelne Analyse ist ein eigenständiges Plugin. Beispiele dafür sind:
- relevante URLs finden
- eine Seite crawlen
- SEO bewerten
- den finalen Report schreiben
Heute liefern wir neun Plugins mit. Morgen können wir ein zehntes ergänzen, ohne den Rest anfassen zu müssen.
Warum das für uns strategisch wichtig ist
Unser Fokus zum Launch war ganz bewusst eine KI-gestützte Analyseplattform für B2B-Websites.
Uns war aber von Anfang an klar: Website-Audits sind nur der erste Schritt.
Durch die Plugin-Architektur können wir Clarity schrittweise um weitere Analyse-Sparten erweitern, ohne die bestehende Plattform umbauen zu müssen. Neue Analyse-Typen sind klar abgegrenzte Module statt tiefgreifender Eingriffe in die gesamte Architektur.
Das bedeutet: Wir können sehr schnell entscheiden, welche neuen Analyse-Bereiche wir als nächstes anbieten möchten und diese iterativ ergänzen.
Templates: Analysen konfigurieren, ohne zu programmieren
Ein Template ist in Clarity im Grunde ein Rezept.
Es definiert:
- welche URLs analysiert werden
- welche Plugins laufen
- in welcher Reihenfolge sie ausgeführt werden
- welche KI-Modelle verwendet werden
- welche Prompts genutzt werden
- wie stark einzelne Ergebnisse gewichtet werden
Ein typisches Template könnte sagen:
„Finde zuerst relevante URLs, wähle die zehn wichtigsten aus, crawle sie, führe vier KI-Analysen parallel aus und verdichte alles zu einem Executive Summary.“
Das Entscheidende dabei: Templates werden in der Oberfläche konfiguriert und nicht im Code.
Dadurch lassen sich neue Analyse-Arten wie „Compliance-Audit“, „Mitbewerber-Deep-Dive“ oder „QA nach Relaunch“ aufsetzen, ohne dass jemand eine Zeile implementieren muss.
Drei Details, auf die wir besonders stolz sind
Frei konfigurierbares, strictly typed Plugin-Output-Schema
Jedes Plugin liefert Ergebnisse in einem klar definierten Output-Schema zurück und dieses Schema ist pro Plugin frei konfigurierbar. So bleibt die Integration robust: API-Clients wissen exakt, welche Felder es gibt, wie sie heißen und welche Typen sie haben.
Möglich macht das ein Type-Generator im Client, der aus den Template-Definitionen automatisch passende TypeScript-Typen erzeugt.
Schreibgeschützte Templates und Snapshots
Sobald ein Template live ist, kann es nicht stillschweigend verändert werden. Änderungen erfordern bewusstes „Unpublishen“.
Das ist auch eine wichtige Voraussetzung für das Type-Generating: Published Templates sind ein stabiler Vertrag, auf dem die generierten Typen basieren können.
Jede Veröffentlichung erzeugt automatisch einen Snapshot. Wenn sich eine Änderung als Fehler herausstellt, reicht ein Klick und die alte Version ist wiederhergestellt.
Das verhindert, dass laufende Analysen plötzlich auf einer anderen Konfiguration basieren und macht Rollbacks genauso banal wie einen Button-Klick.
Template-Verkettung
Ein „Deep-Dive“-Template kann Ergebnisse eines früheren „Quick-Scan“-Laufs übernehmen, statt die Website erneut komplett zu crawlen. Das spart Zeit, Rechenleistung, KI-Kosten und sorgt gleichzeitig für konsistente Reports.
Wie ein Analyse-Lauf tatsächlich abläuft
Klickt jemand auf „Analyse starten“, beginnt im Hintergrund eine kleine Choreografie.
Die Kurzfassung:
- Die API nimmt den Request entgegen und legt einen Job in die Queue.
- Ein separater Worker übernimmt die Analyse.
- Der Worker zerlegt das Template in Abhängigkeits-Wellen.
- Plugins, die unabhängig voneinander laufen können, werden parallel ausgeführt.
- Ergebnisse werden live per WebSocket an die Oberfläche gestreamt.
- Das finale Synthese-Plugin erstellt daraus den Abschlussbericht.
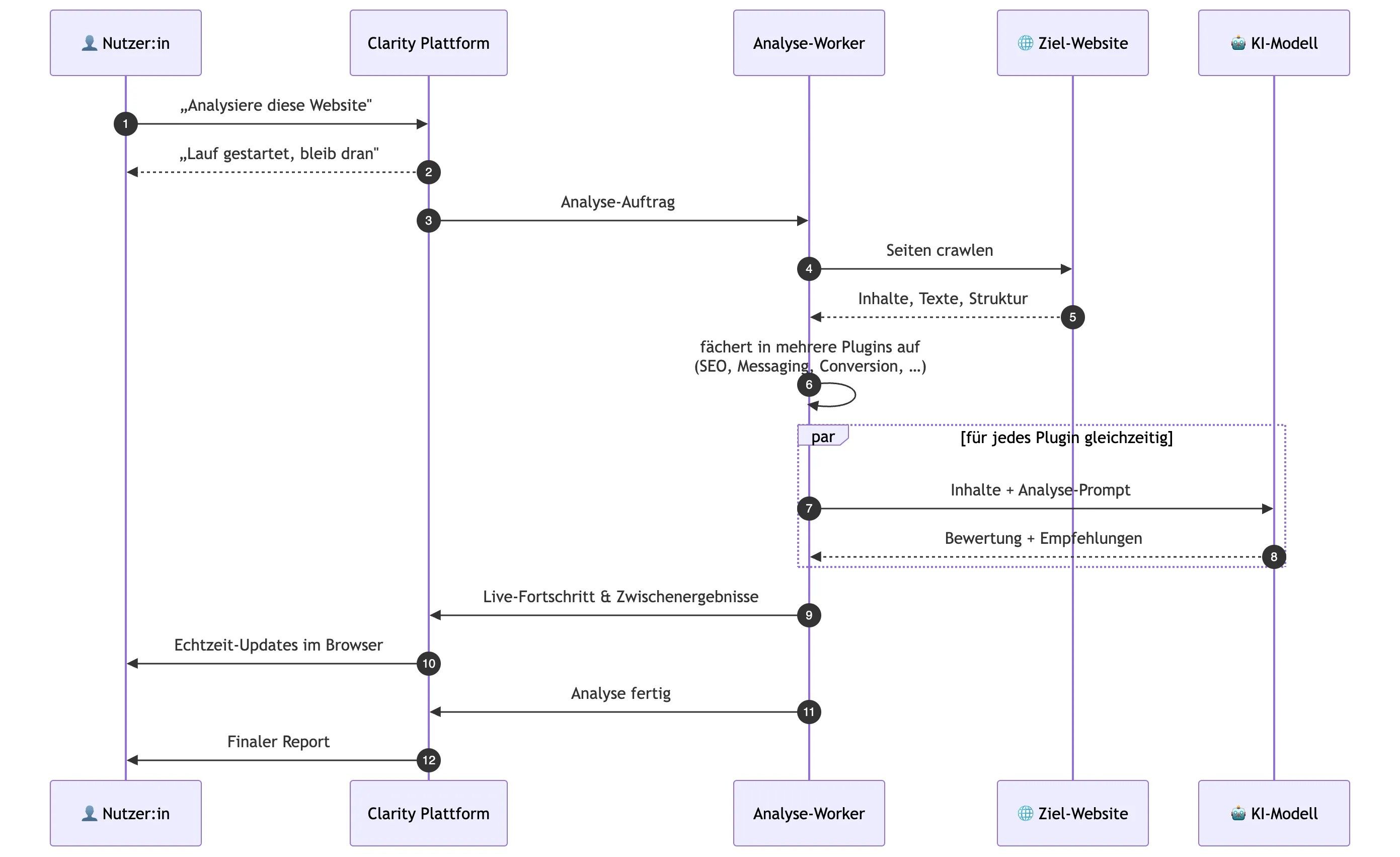
Warum API und Worker getrennt sind
Eine Analyse kann mehrere Minuten dauern. Würde die API diese Arbeit selbst ausführen, würden alle anderen Requests langsamer werden. Deshalb läuft die schwere Arbeit separat, wahlweise als Child-Prozess, Docker-Container oder Kubernetes-Pod.
Die API bleibt dadurch reaktionsschnell, während sich Worker unabhängig skalieren lassen. Und das Beste:
Die gleiche Business-Logik läuft lokal, im eigenen Rechenzentrum oder in Kubernetes.
Crawling mit echten Browsern
Viele klassische SEO-Tools analysieren nur statisches HTML.
Das Problem: Moderne Websites bestehen aus JavaScript, dynamischem Rendering und clientseitiger Logik.
Deshalb nutzt Clarity Playwright + Chromium und lädt Seiten in echten Browsern.
Das bringt einige Vorteile:
- Inhalte werden tatsächlich gerendert
- Lazy Loading funktioniert
- clientseitige Navigation wird sichtbar
- Accessibility-Probleme lassen sich realitätsnah prüfen
- die KI analysiert dieselbe Seite, die echte Nutzer:innen sehen
Die KI-Schicht: Warum wir auf Claude setzen
Alle KI-Plugins in Clarity arbeiten mit Anthropic Claude, aktuell standardmäßig mit Sonnet 4.6.
Wir haben unterschiedliche Modelle getestet. Claude hat uns vor allem aus zwei Gründen überzeugt:
- sehr stark bei langen, unstrukturierten Webseiten-Inhalten
- gute Ergebnisse bei analytischen Aufgaben und strukturierten Bewertungen
Was dabei technisch wichtig ist
Streaming
Wir streamen KI-Antworten, damit lange Analysen nicht in Timeouts laufen und der Fortschritt in der Oberfläche sofort sichtbar ist.
Retries mit Backoff
Wenn das Modell bei hoher Last kurzzeitig „overloaded“ zurückgibt, wartet das System automatisch und versucht es erneut. Das reduziert Abbrüche, ohne dass Nutzer:innen etwas davon mitbekommen.
Token-Tracking
Pro Lauf erfassen wir Input- und Output-Tokens sowie Cache-Lese- und Schreibzugriffe. So können wir Kosten pro Plugin und pro Template nachvollziehen und sauber kalkulieren.
Dry-Run-Modus
Templates testen wir vollständig, ohne echte KI-Aufrufe auszuführen. Die Pipeline verhält sich dabei wie im Echtbetrieb, nur mit definierten Platzhalter-Ergebnissen. Das ist besonders hilfreich für Entwicklung, QA und Debugging.
Praxiserprobte Infrastruktur
Die spektakulären Teile sind KI und Crawling. Die wichtigen Teile sind bewusst konservativ gewählt.
Datenbank: PostgreSQL
Bewährt, stabil und battle-tested. Die Datenbank ist der Teil des Systems, bei dem absolut nichts verloren gehen darf.
Queue-System: Redis + BullMQ
Redis übernimmt die Job-Queues, das Echtzeit-Pub/Sub und die Kommunikation zwischen Worker und API. BullMQ orchestriert darauf die Analyse-Pipeline.
TypeScript überall
Backend und Frontend teilen sich Typen. Wenn sich ein Datenbank-Feld ändert, merken wir das im Build und nicht erst später in Produktion.
Monorepo mit pnpm und Turborepo
Mehrere Pakete teilen sich Infrastruktur. Builds werden gecached, Deployments bleiben schnell und reproduzierbar.
Hono als HTTP API
Für die API nutzen wir Hono: leichtgewichtig, gut typisierbar und für unseren Use-Case schnell genug, ohne unnötigen Overhead.
Moderner Frontend-Stack fürs Admin-UI
Für das Admin-UI setzen wir auf einen weit verbreiteten Stack aus React, TanStack Query und Tailwind. Für die UI-Komponenten nutzen wir shadcn/ui, damit wir volle Kontrolle über den Code behalten.
Authentifizierung und Integrationen
Neben normalen Benutzerkonten unterstützt Clarity zwei Arten von API-Zugängen.
Personal Tokens
Für einzelne Personen, die automatisiert mit der Plattform arbeiten wollen.
App Tokens
Für externe Integrationen und Partner-Systeme.
Dabei lassen sich Tokens auf bestimmte Templates einschränken. Eine Integration kann also nur genau die Analysen starten, die sie darf.
Alle Tokens können jederzeit widerrufen werden.
Unspektakulär, aber wichtig.
Echtzeit-UI statt Lade-Spinner
Nichts fühlt sich kaputter an als eine lange Analyse ohne Feedback.
Deshalb streamt Clarity jede Statusänderung live in die Oberfläche:
- Plugin startet
- Plugin meldet Fortschritt
- Plugin liefert Zwischenergebnisse
- Plugin abgeschlossen
Eine DAG-Ansicht visualisiert den gesamten Analyse-Graphen in Echtzeit.
Man sieht:
- welche Plugins laufen
- welche warten
- welche abgeschlossen sind
- wie viele Tokens verbraucht wurden
- wie sich die Analyse Schritt für Schritt aufbaut
Statt vor einem Spinner zu sitzen, beobachtet man den Prozess live.
Clarity ausprobieren: kostenloser Report, optionaler Deep-Dive
Clarity ist nicht „ein Analyzer für alles“, sondern liefert bewusst optimierte Analysen für B2B-Webseiten.
Wer es ausprobieren möchte: https://liechtenecker.at/clarity
Dort lässt sich ein kostenloser Report generieren. Falls man nicht auf die Analyseergebnisse warten möchte, kann man eine E-Mail-Adresse hinterlassen und wird automatisch benachrichtigt, sobald die Ergebnisse bereitstehen. Danach kann man den passenden Deep-Dive dazubuchen.
Fazit
Clarity zeigt ziemlich gut, wie wir bei Liechtenecker Technologie verstehen:
Moderne Architektur, pragmatische Entscheidungen und Systeme, die nicht nur heute funktionieren, sondern auch in zwei Jahren noch wartbar und erweiterbar sind.
Wenn du Clarity live sehen möchtest, zeigen wir dir gerne:
- wie der Analyse-Graph aufgebaut wird
- wie der Crawler arbeitet
- wie KI-Plugins streamen
- wie daraus am Ende ein verwertbarer Report entsteht
Melde dich gerne bei uns, wir freuen uns :)